1장. 데이터베이스란 - 용도와 역할
데이터베이스의 기본기능
1. 데이터 조작(검색, 등록, 수정, 삭제)
2. 동시성 제어
3. 장애 대응
4. 보안
데이터베이스의 기본 기능 - 동시성 제어
-> 파일 하나를 열람 하고 있을때 새로운 열람 요청을 제한 하거나 그 다음 사람을 읽기 모드로만 볼수 있게 한다 등등
NoSQL 데이터 베이스
-> Not Only Sql, 여기서 sql이란 관계형 데이터 베이스를 만들기 위한 언어를 의미, 관계형 데이터베이스에 있는 기능 일부를 버려서 성능(처리속도)을 높이고 있다
2장. 관계형 데이터베이스란 - 가장 대표적인 데이터베이스
* DBMS와 데이터베이스의 차이 -> '데이터베이스'라는 것은 기능이나 구조를 나타내는 추상적인 개념이고, 'DBMS'는 그것을 실현하기 위해 작성된 구체적인 소프트웨어를 가리킵니다.
* 소프트웨어 계층성
1.운영체제
-> 시스템을 동작하게 하기 위한 일종의 토대가 되는 기능을 제공하는 소프트웨어
2.미들웨어
-> 애플리케이션에 없는 기능을 이용하기 위해 추가하는 것으로 알고 있다.
3.애플리케이션
-> 사용자가 가장 빈번하게 조작하는 소프트웨어
3장. 데이터베이스에 얽힌 돈 이야기 - 초기비용과 운영비용
4장. 데이터베이스와 아키텍처 구성 - 견고하고 고속의 시스템을 구축하기 위해
웹 서버 계층
-> 클라이언트로부터 접속 요청을 직접 받아서 그 처리를 뒷단의 애플리케이션 계층에 넘기고 그 결과를 클라이언트에게 반환합니다. 즉 애플리케이션 서버와 클라이언트 웹 브라우저와의 가교 역할입니다.(Apache, nginx)
애플리케이션 계층
-> 비즈니스 로직을 구현한 애플리케이션이 동작하는 층, 웹 서버로부터 연계된 요청을 처리하고, 필요하면 데이터 베이스 계층에 접속해 서 데이터를 추출하고 이를 제공한 결과를 웹 서버로 반환합니다.(tomcat, passenger, puma)
다중화 -> 저장소는 하나를 공유하게 되므로 저장소가 부서질 경우에는 데이터 손실이 잃어난다
1. Active-Active 클러스터를 구성하는 컴포넌트를 동시에 가동한다.
2.Active-Standby 클러스터를 구성하는 컴포넌트중 실제 가동하는 것은 Active, 남은 것은 대기 하고 있는다.
리플리케이션 -> db 서버와 저장소를 그대로 복제 하는 개념
(마스터 - 슬레이브 방식)
데이터베이스의 아키텍쳐 패턴
stand-alone
클러스터링 -> shared nothing
-> shared disk -> active-active
-> active-standby -> hot-standby
리플리케이션 -> 마스터 슬레이브
-> 멀티 마스터
샤딩 -> 해쉬를 이용해 1~100번 까지는 1번 db, 100~1000번 까지는 2번 db 이런식으로 구성하는 것
5장. DBMS를 조작할 대 필요한 기본 지식 - 조작하기 전에 알아두어야 할 것
커넥션이란 -> ex) 사용자와 mysql이 접속되었다. 즉 연결되었다는 뜻
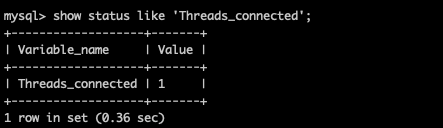
mysql의 threads_connected값 -> 현재 로그인한 사람
show status like 'Uptime' -> 가동된 시점으로부터의 시간
show status like 'Queries' -> 실행한 sql문 수
* 데이터 베이스를 조작하는 수단은 sql 외에 관리 명령이 있다.
* 데이터베이스는 4계층 또는 3계층으로 구조화되어 있다.
* 계층은 위에서부터 차례로 인스턴스 -> 데이터베이스 -> 스키마 -> 오브젝트다
* 3계층 구조는 데이터베이스와 스키마 계층을 실직적으로 생략하고 있다(Oracle과 Mysql)
6장. SQL 문의 기본 - SELECT 문의 이해
distinct 는 group_by와 동일한 결과를 출력해낼수 있다
select distinct district from city where countrycode ='KOR';
select district from city where countrycode ='KOR' group by district;

group_concat 으로 한 행으로 출력할수도 있다
집약한 값(max, min, avg, count, sum) 에는 where을 쓸수가 없다. 대신 having을 써야한다.
-> select district, count(*) from city where countrycode = 'KOR' and count(*) = 4 group_by district (X)
-> select district, count(*) from city where countrycode = 'KOR' group_by district having count(*) = 6;
업데이트
-> update 테이블이름 set 칼럼명 = 값 조건문
dml -> (select, update, delete, insert)
7장. 트랜잭션과 동시성 제어 - 복수의 쿼리 통합
트랜잭션 -> 한 덩어리의 쿼리 처리 단위
Atomity - 원자성(전부 성공하거나 전부 실패하거나)
Consistency - 일관성(사용자의 id 부여 개념과 같음)
Isolation - 독립성(같은 데이터를 복수의 사용자가 조작해도 모순 없이 실행되는 것을 보증한다) -> 이것을 조절하기 위해 격리수준을 조절한다.
Durability - 지속성(한번 커밋된 것은 계속 지속이 된다)
8장. 테이블 설계의 기초 - 테이블의 개념과 정규형
9장. 백업과 복수 - 장애에 대비하는 구조
10장. 부록_성능을 생각하자 - 성능 향상을 위해
인덱스의 이점
- SQL 문을 변경하지 않아도 성능을 개선할 수 있따
- 테이블의 데이터에 영향을 주지 않는다
- 일정한 효과를 기대할 수 있다
데이터베이스에서는 인덱스로 설정을 하면 해당 칼럼은 B-TREE로 구성된다
B-TREE 핵심 -> 정렬을 유지하고 있다.
인덱스 작성이 역효과가 나는 예
- 인덱스 갱신의 오버헤드로 갱신 처리의 성능이 떨어진다
하나 변경하면 순서가 정렬이 되어야해서 전부 정렬되는데 이때 참조해야할 칼럼들이 많아지면 갱신 자체가 너무 늦게 된다.
SELECT문을 고속화 할수 있는것은 INSERT나 UPDATE같은 갱신 SQL은 늦어진다
- 의도한 것과 다른 인덱스가 사용된다
데이터 베이스의 최적화를 결정하는(ex. 어떤 경로로 어떻게 데이터에 접근해야 할지) 옵티마이저에게 다른 의도로 인덱스가 전달된다
'책' 카테고리의 다른 글
| 견디는 힘(불확실한 오늘을 잘 버티기 위한 5가지 기술) (2) | 2021.09.26 |
|---|---|
| 무뚝뚝해도 괜찮습니다(타인에게 휘둘리지 않고 나답게 사는 법) (0) | 2021.09.26 |
| 읽기 좋은 코드가 좋은 코드다 (0) | 2020.12.26 |
| 아키텍트 이야기 (0) | 2020.12.25 |
| 타이탄의 도구들 (1) | 2020.12.25 |